Travel · Yacht charter
ForSailors: one yacht search built from three charter systems that disagree
A German charter agency needed one search across three booking systems. We merged their catalogs into one fleet and shipped it on Google Kubernetes Engine.
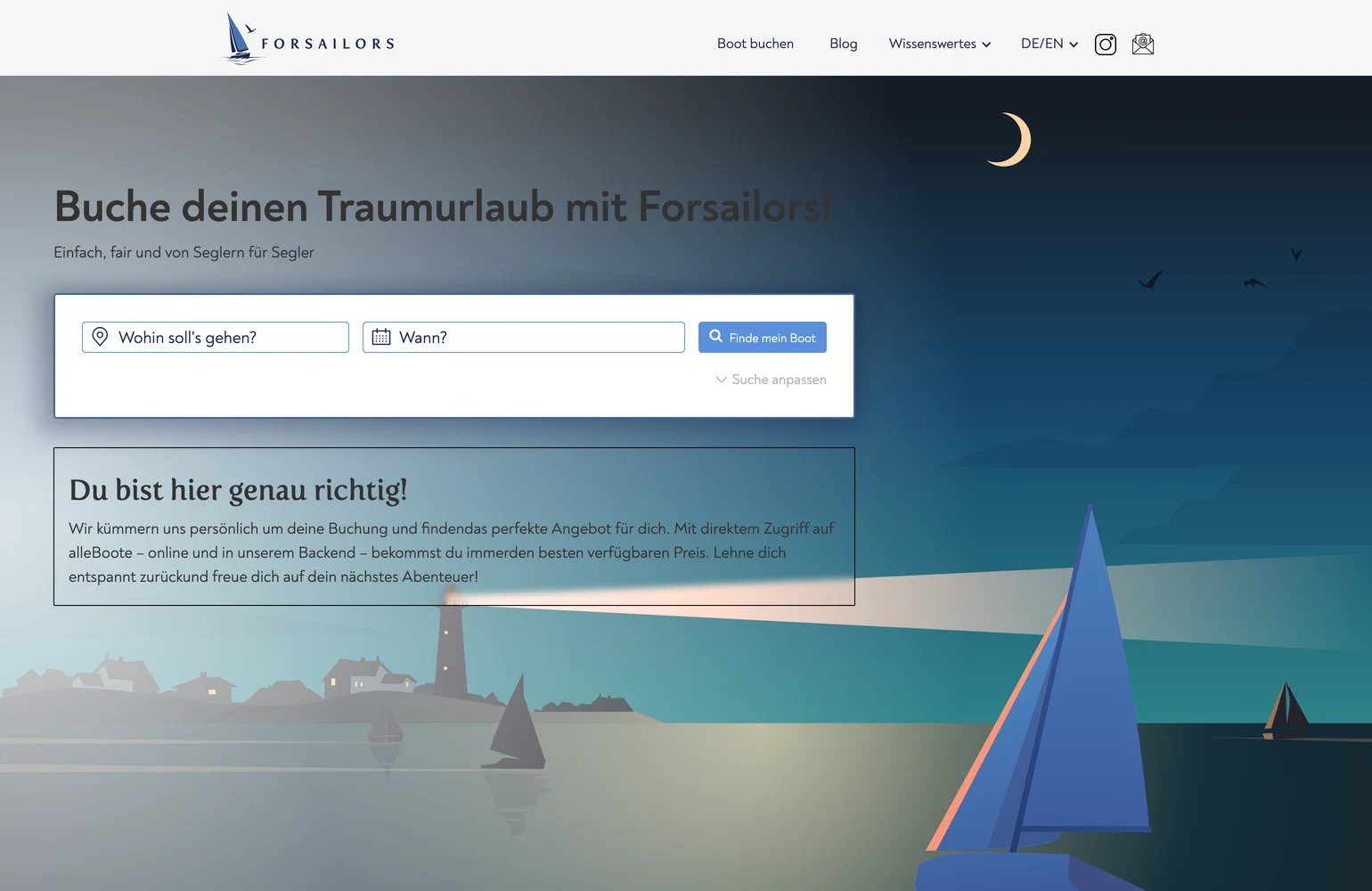
The story behind
ForSailors is a German yacht charter agency, by sailors for sailors, as the homepage puts it. The brief was one honest search across the fleets they broker. The catch is where charter fleets live: inside the industry's booking systems, and three of them mattered. NauSYS and Booking Manager speak REST, Yachtsys speaks SOAP, and each has its own IDs, its own price model, and its own spelling of the same yacht. Listed raw, one boat shows up twice at two prices. Sailors notice.
So the platform never queries those APIs while a visitor waits. Downloaders pull each catalog into PostgreSQL, 23 entity kinds from NauSYS alone, countries down to discount rules. Converters normalize them into one model, then 21 mergers decide which records are the same thing. Yachts match on normalized name plus charter company, after a pass that fixes the typos charter staff actually type. One company's fleets were double-listed so consistently that the merger carries a hard exclusion for them. And every record change lands in time-partitioned history tables, so when a price looks wrong we can prove which feed changed it, and when.
Business value
- One search across every brokered fleet, not three browser tabs into three systems.
- A yacht appears once, with one price list, whichever system it came from.
- Upstream APIs sit behind a cache and a sync, never in the visitor's critical path.
- German and English served from one codebase, switched by a cookie, not two sites.
Project scope
- Sync pipeline for three charter systems: NauSYS, Booking Manager, and SOAP-based Yachtsys.
- A unified fleet model in PostgreSQL, with per-source converters and 21 cross-source mergers.
- Server-rendered search, yacht detail, and booking request flow in ASP.NET MVC.
- CacheProxy, a standalone HTTP cache service with per-request TTL headers.
- RecordHistory, change tracking into time-partitioned Postgres tables.
- German and English localization with gettext .po files.
- Kubernetes deployment on Google Cloud, with a Cloud Build pipeline per service.
Deliverables
- The forsailors.com web app, 28 projects and 58,408 lines of C#.
- Three data-source integrations, NSwag-generated REST clients and one SOAP client.
- The merge layer that turns three catalogs into one fleet.
- CacheProxy, deployed as its own service with a persisted request log.
- GKE manifests and Cloud Build CI for every deployable.
Tech stack
Frequently asked
Why is this case study named when others are anonymized?
Our healthcare engagements are anonymized by contract, so those studies show architecture, not brands. ForSailors is a public consumer site, the work is visible at forsailors.com, and there is no compliance boundary in the way. When we can show the real thing, we do.
Why sync everything into a database instead of querying the booking APIs live?
Because a visitor should never wait on a third party. The charter APIs are slow, rate-limited, and one of them is SOAP. Search reads our PostgreSQL copy, the sync keeps it fresh, and the CacheProxy keeps even the sync polite. The price is a pipeline you have to watch, so we shipped the logging and request history to watch it with.
How do you know two listings are the same yacht?
Name plus charter company, after normalization that fixes the data-entry errors the feeds actually contain. Matching runs inside 21 entity mergers, one per concept: yachts, companies, locations, price lists, equipment, seasons. Where a fleet is double-listed upstream on purpose, the merger carries an explicit exclusion instead of a guess.
Can you build this kind of aggregation for our market?
Yes. Download, normalize, merge, serve from your own store. The pattern transfers to any market where inventory lives in several upstream systems, from equipment rental to real estate. The merge rules are the real work, and they come from reading the data, not the API docs. Book a consultation call and bring your worst duplicate.
Have a workflow that needs this?
Tell us the shape of the problem. Scoped estimate, usually within 3 to 5 business days. No card, no obligation.
Estimate this buildor email business@highcraft.ioMore work
Quell focus app
A focus app that generates a 40 Hz binaural beat, a neural-voice coach, and AI music on the device. No accounts, no server, works offline.
WebReaper
One small binary turns any site, bot-checks included, into clean Markdown or structured data for your LLM. MIT licensed, bring your own model.
WriteText
WriteText is a menu-bar Mac app that rewrites a selection where it already sits, in Mail, Slack, or anything else, through the LLM provider you bring.