Developer tools · Web scraping
WebReaper: a single-binary web scraper that climbs from HTTP to stealth to get through
One small binary turns any site, bot-checks included, into clean Markdown or structured data for your LLM. MIT licensed, bring your own model.
Live demo
Watch it climb
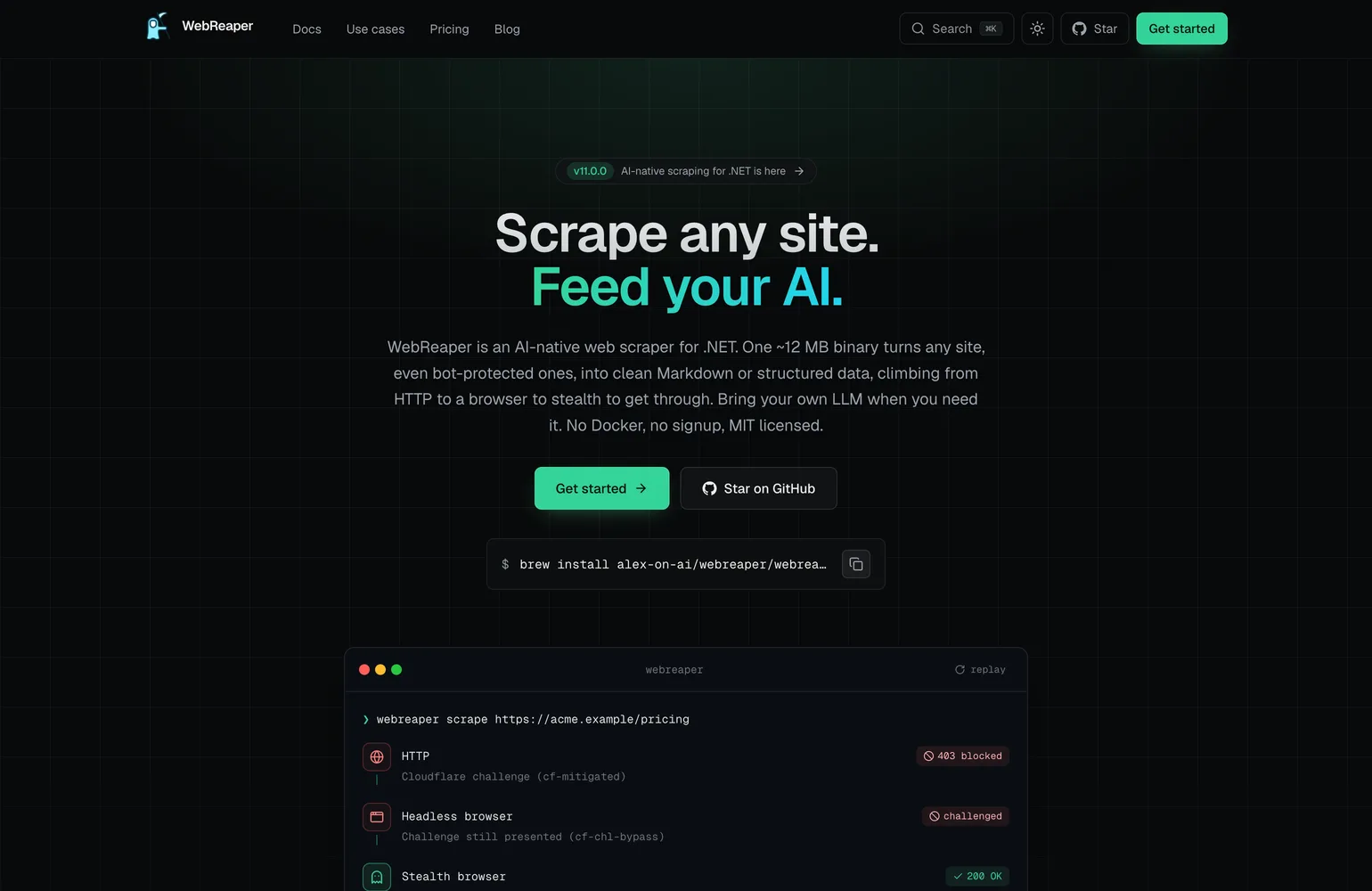
A recorded run against a Cloudflare-protected page. A plain HTTP fetch and a vanilla headless browser are challenged; the stealth rung gets through and returns clean Markdown.
- HTTPqueued
- Headless browserqueued
- Stealth browserqueued
The story behind
A scraper is easy until the page fights back. Clean Markdown from a static page is the simple part. The other part is bot checks, JS-rendered apps, and the block that still returns a 200. Most tools make you choose a browser up front and guess which sites need one. WebReaper starts on a fast HTTP fetch and climbs to a real browser, then to stealth, only when a page actually looks blocked. The climb is per page and host-sticky: the first confirmed block on a host lifts that host's floor, so the rest of a crawl starts at the tier that works instead of re-paying the one that failed.
A challenge page written to your output as if it were data is worse than a clean failure, because everything downstream trusts it. A vector store does not know it just indexed a CAPTCHA. So the rule was plain: clean data or a clear non-zero exit, never a challenge page wearing a 200. A blocked page is dropped, the run exits non-zero, and an unattended job knows something went wrong.
Business value
- Any site becomes clean Markdown or typed data a model can read, with no glue code.
- Bot checks stop being a manual problem; the scraper detects the block and climbs on its own.
- Nothing to host and no signup: one binary on PATH, MIT licensed, fine to embed in commercial code.
- Bring your own model, so the AI features cost tokens only when you ask for them.
Project scope
- A crawl engine with swappable transport, scheduler, visited-link tracker, and result sink.
- Block detection with per-page, host-sticky escalation from HTTP to a headless browser to a stealth backend.
- Deterministic extraction from CSS and XPath to Markdown, with an opt-in LLM fallback and self-healing selectors.
- A Native-AOT CLI, a .NET library, and MCP servers over stdio and Streamable HTTP.
Deliverables
- A single self-contained binary across six platform targets, codesigned and notarized on macOS.
- The .NET library on NuGet and a bundled Claude Code skill via webreaper init.
- A compile-time schema source generator that stays reflection-free for AOT.
- Distribution through Homebrew, an install script, and GitHub Releases.
Tech stack
Frequently asked
Is WebReaper really free?
Yes. The library, the CLI, and the Claude Code skill are MIT licensed and free to use, fork, and embed in commercial software. Optional hosted Cloud and Enterprise tiers add managed scheduling and proxies later, but the core does everything locally.
How is it different from Firecrawl?
Firecrawl is a hosted, AGPL-licensed cloud service. WebReaper is a local-first, MIT-licensed single binary and .NET library. You run it yourself, embed it in closed-source code, and bring any LLM.
Do I need an LLM to use it?
No. WebReaper is deterministic by default: CSS and XPath selectors and clean Markdown need no model. The AI features (an LLM fallback, schema inference, an autonomous agent) are opt-in and bring-your-own-model, so you pay for tokens only when you ask for them.
Can it get through Cloudflare or DataDome?
A plain scrape already climbs from HTTP to a real browser when a page looks blocked. Add stealth for Cloudflare, DataDome, and PerimeterX. A page still blocked at the top tier is dropped, never returned as data.
Can you build something like this for us?
Yes. The crawl engine, the escalating loader, and the schema and LLM-fallback pipeline are patterns we can put on your own infrastructure or product.
Have a workflow that needs this?
Tell us the shape of the problem. Scoped estimate, usually within 3 to 5 business days. No card, no obligation.
Estimate this buildor email business@highcraft.ioMore work
Quell focus app
A focus app that generates a 40 Hz binaural beat, a neural-voice coach, and AI music on the device. No accounts, no server, works offline.
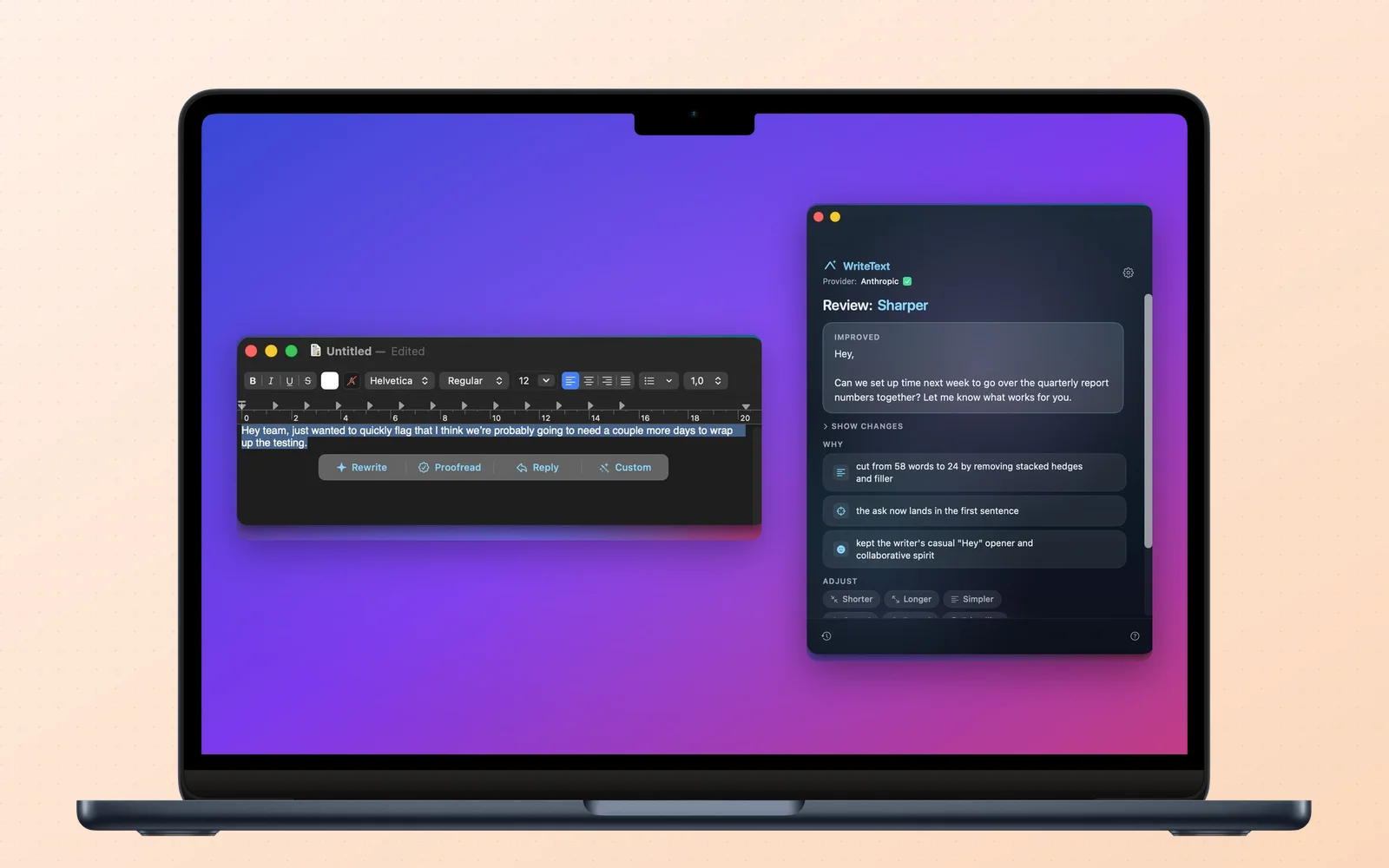
WriteText
WriteText is a menu-bar Mac app that rewrites a selection where it already sits, in Mail, Slack, or anything else, through the LLM provider you bring.
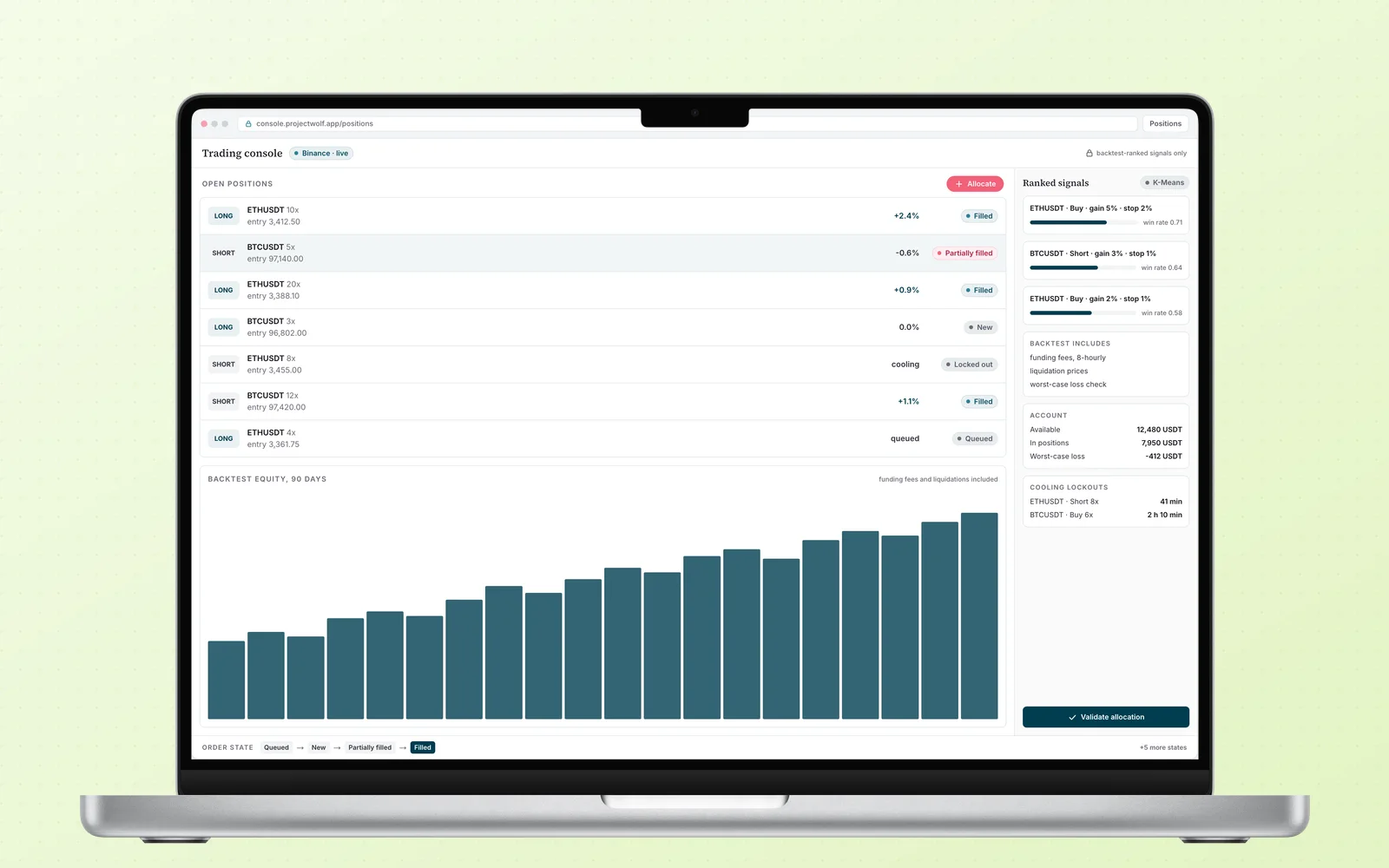
Project Wolf
An AI-signal futures platform for Binance. K-Means clustering ranks the trades, a state-aware engine executes them, and risk controls keep the account alive.